




|
|
|
|
by Yvette Depaepe
Published the 22nd of July 2026
Today marks a truly special milestone for everyone who is part of the 1X community.
According to The 50 Best Photography Blogs (updated July 20, 2026),
1X has been ranked the 3rd best photography magazine/blog in the world.
This remarkable recognition is a testament to the passion, creativity, and dedication that have shaped our magazine over the years.

‘Typing up a storm’ by Colin Dixon
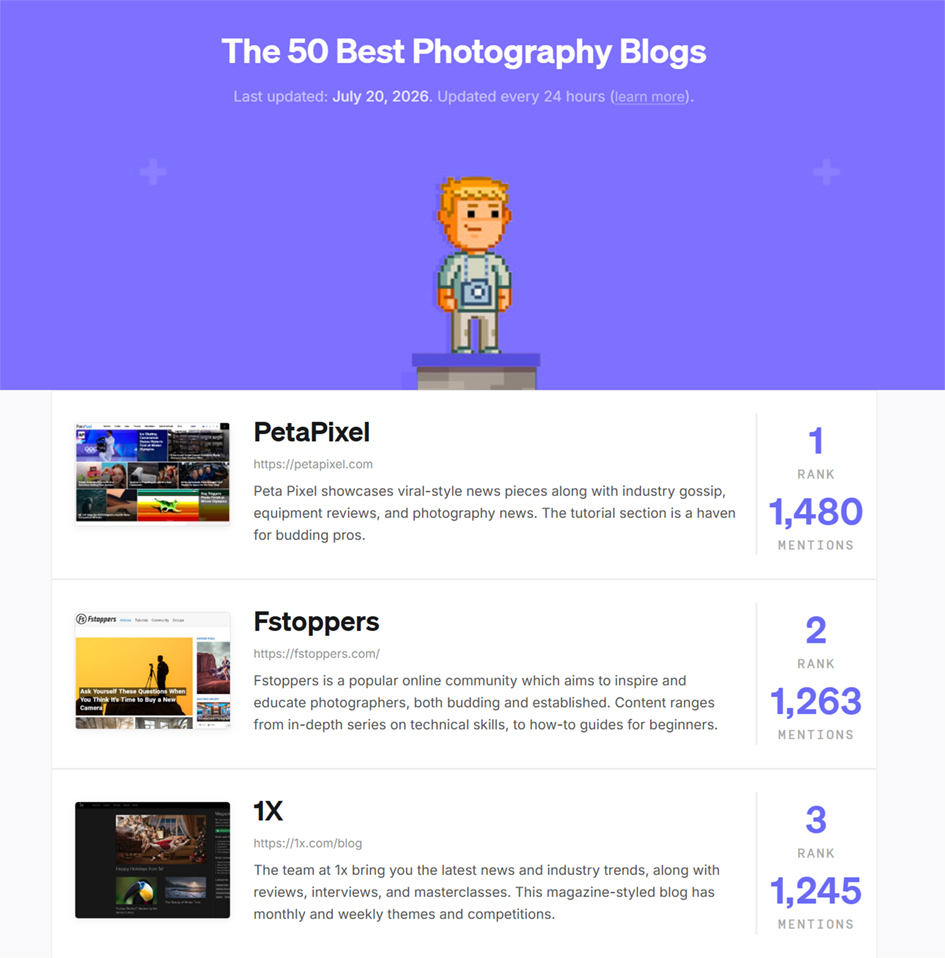
The 50 Best Photography Blogs of 2026 - Detailed.com
As Editor in Chief, I am incredibly proud—not only of this achievement, but of the extraordinary people who made it possible.
Together with our team of 13 dedicated editors, we have worked tirelessly to bring photographers from around the world inspiring stories, educational writngs, thought-provoking interviews, honest reviews, and so many more photogrphy relaterd studies. Every article we publish reflects our shared commitment to excellence and our belief that photography is a universal language capable of connecting people across cultures and generations.
This recognition belongs to every member of our editorial team. Their professionalism, artistic vision, attention to detail, and countless hours of volunteer work continue to make 1X Magazine a trusted source of inspiration for photographers of every level, for artists who make this community so inspiring.

‘Writer’s block’ by Adrian Donoghue

‘Spilled Letters’ by Dina Belenko
Most importantly, our deepest gratitude goes to you—our readers.
Whether you have been with us since the beginning or have only recently discovered 1X, your enthusiasm, encouragement, comments, and continued support inspire us every single day. Every visit, every shared article, every competition entry, and every photograph submitted strengthens this unique community that we are so fortunate to be part of.
If our articles have informed you, inspired you, or simply made you pause for a moment, we'd love to hear your thoughts. A short comment beneath an article can spark meaningful conversations, encourage our authors, and strengthen the sense of community that makes 1x unique. Your engagement does more than support our writers—it also helps increase the visibility and impact of the magazine.
With your participation, we have a genuine opportunity to move from third place to second in the global rankings.
Every thoughtful comment counts.
Join the conversation. Share your perspective. Help us take the next step—together.

by Dr Roland Shainidze
Photography is far more than creating beautiful images. It is about telling stories, preserving moments, expressing emotions, and inspiring others to see the world through different eyes. We are honored to be able to share that journey with you.
Being recognized as the third-best photography magazine / blog worldwide is not a destination—it is motivation to continue raising the bar. We remain committed to delivering exceptional content, celebrating outstanding photographers, and fostering a vibrant global community where creativity thrives.
On behalf of our entire editorial team, thank you for your trust, your loyalty, and your passion for photography.
Together, we look forward to the next chapter.
With sincere appreciation,
Yvette Depaepe
Editor in Chief
1X Magazine

by Nick Walton
 | Write |
 | Louie Luo PRO Well-deserved honor - congratulations to you, dear Yvette, and the entire 1x team! |
 | Yvette Depaepe CREW Thank you so much, Louie ... ♥ |
 | Adolfo Urrutia PRO It's a great joy that your hard work, dedication, and talent have been rewarded with this award. Congratulations to the whole team! |
| Yvette Depaepe CREW Many thanks for your appreciation, Adolfo! |
 | Andy Dauer PRO congratulations and many thanks to all! |
| Yvette Depaepe CREW Thanks in the name of all, Andy! |
 | Yinghui Dan PRO Remarkable achievement, thank Yvette, your team and all members! |
| Yvette Depaepe CREW Thanks a lot in the name of the whole 1x community, Yinghui Dan! |
 | Christoph Eichbichler PRO Chapeau to the 1x Team!!! |
| Yvette Depaepe CREW Many thanks Christoph! |
 | Chris Hamilton PRO Great achievement, well deserved. |
| Yvette Depaepe CREW Thanks a lot, Chris! |
 | Eiji Yamamoto PRO Amazing news! Dear Yvette and the team—thank you so much and congratulations! I look forward to 1X continuing to be a source of inspiration! |
| Yvette Depaepe CREW You can count on us, dear Eiji ... ♥ |
 | Patrick Compagnucci PRO A wonderful achievement! Congratulations to all, |
| Yvette Depaepe CREW Thanks in the name of all, Patrick! |
 | Pier Luigi Calosso PRO Brilliant, well deserved. Thank you, Yvette, for your skill. |
| Yvette Depaepe CREW Thanks for your kind appreciation, Pier Luigi ... |
 | joanaduenas PRO Well-deserved recognition and applause to the 1x team. Thanks for sharing Ivette!! |
| Yvette Depaepe CREW My pleasure and proudness, Joana ;-) |
 | Renato Duarte da Cunha Congratulations! A more than well-deserved award! |
| Yvette Depaepe CREW Thank you, dear Renato! |
 | Colin Dixon CREW Fabulous achievement from everyone involved and especially to Evette |
| Yvette Depaepe CREW So many thanks, dear Colin ... And you too as a fine editor ;-) |
 | Cicek Kiral CREW Thanks to all the team and congratulations to all. |
| Yvette Depaepe CREW Many thanks from us all, dear friend! |
| | Cicek Kiral CREW I am Proud to be part of 1x both as photographer and crew ❤️ |
| Yvette Depaepe CREW And we are glad with you too, dear Cicek ♥ |
 | LARRY BUTTERWORTH PRO Very well deserved. Congrats |
| Yvette Depaepe CREW Many thanks, Larry ♥ |
 | Gary Duan PRO Congratulations! A lot of hard work went into these magazines. Thanks for consistently providing such resourceful and insightful content. |
| Yvette Depaepe CREW Thanks from us all, dear Gary! |
 | Mei Xu PRO what a marvelous achievement! Thank Yvette, editorial team and all of excellent photographers at 1x to make it possible. |
| Yvette Depaepe CREW Thanks in the name of us all, dear Mei! |
 | Rana Jabeen PRO This is a proud moment for all of us at here at 1x! The dedication and hard work of the entire Editorial Team is visible in each of your magazine articles. Congratulations and best wishes to Yvette and all members of the team. Waiting to reach Number 1 ♥️ |
| Yvette Depaepe CREW First nr 2 and yes ... all together up to nr 1! Thank you, dear Rana! |
 | Ed Williams PRO I'm new here and very proud to be associated with 1x.com. This magazine recognition is both remarkable and earned! |
| Yvette Depaepe CREW Thanks Ed and welcome in our warm community! |
 | Marie Salmeron-Serrano PRO I am very happy about this!, Congratulations to 1x.com! |
| Yvette Depaepe CREW Thanks a lot, dear Marie! |
 | John-Mei Zhong PRO Wow, what a great achievement! Yvette. We are so happy for you and your wonderful editing team. Sending you the biggest congratulations—we are all so proud of everything you’ve accomplished! |
| Yvette Depaepe CREW Many many thanks, my dearest friends! |
| | John-Mei Zhong PRO Wow, what a great achievement! Yvett. We are so happy for you and your wonderful editing team. Sending you the biggest congratulations—we are all so proud of everything you’ve accomplished! |
 | Manuel Gayoso PRO Congratullations to the 1X team and editors on this great achievement!! |
| Yvette Depaepe CREW Thanks in the name of us all, Manuel! |
 | Mark Seawell PRO Well done! |
| Yvette Depaepe CREW Thank you, Mark! |
 | Molly Fu (APA) PRO What a successful achievement, congrats dear Yvette and your team!!! |
| Yvette Depaepe CREW Many thanks, dear Molly ;-) |
 | Robin Wechsler PRO How very wonderful! Congrats to all of you! |
| Yvette Depaepe CREW Thanks in the name of all, dear Robn! |
 | Robert Suditu PRO Great job, you, guys! You are fantastic and you deserve the best! For us, you are no. 1! |
| Yvette Depaepe CREW Such a sweet reaction, Robert! Thanks a lot! |
 | John Fan CREW Great job, Yvette! Congratulations! |
| Yvette Depaepe CREW Many thanks, dear John!!! |
 | Ralf Steinberg PRO What a fantastic achievement! Congratulations to everyone on the team. |
| Yvette Depaepe CREW Thank in the name of us all, Ralf ;-) |
 | Alberto de la Cruz PRO Congratulations to the entire 1X team on this well-deserved recognition! Achieving third place worldwide reflects the tremendous work, dedication, and care behind every article and every photograph published. As a reader, it is appreciated to find a magazine that not only showcases high-quality images, but also inspires, teaches, and fosters a community where something new is always learned. Hopefully this achievement will be a boost to continue growing and, who knows, reach that second place very soon. Thank you for continuing to support photography with such passion. |
| Yvette Depaepe CREW Thank you so much for your appreciation, Alberto ...2nd place is not far away anymore. Let's go together for the 1st place ;-) |
 | 大山 儀高 PRO That’s amazing! What a wonderful achievement.
This is a momentous occasion that further recognizes Yvette’s hard work and the talent of 1X artists.
I, too, am where I am today because I read the 1X columns and was inspired by the work of these wonderful artists. That is an undeniable fact.
That’s exactly why I’m so happy about this achievement.
Congratulations!! |
| Yvette Depaepe CREW Oh thank you for your lovely and praising comment, dear friend! |
 | Atul Saluja PRO This is such a great achievement. Huge congratulations Yvette for all your hard work, and to the team and photographers at 1X. |
| Yvette Depaepe CREW Thanks Atul in name of everybody, the team, the readers and all members of our community. |
 | Marius Cinteza CREW Great news, Dear Yvette! Thanks for sharing! A huge thank you to you and everyone who contributed to getting this across the finish line. Fantastic effort! |
| Yvette Depaepe CREW Thank you dear Marius, editor and friend ♥ |
 | Peter Davidson CREW Well done to all, but especially to Yvette on her perserverance and commitment to the Magazine. |
| Yvette Depaepe CREW Thank you so much, my precious friend and assistend editor ;-) |
 | Ineke Mighorst PRO Great,super, more then words can express. Congratulation team. |
| Yvette Depaepe CREW Thank you so much, Ineke! |
 | Sokol Priftaj PRO Fantastic news! Huge congrats |
| Yvette Depaepe CREW Thanks a lot, Sokol! |
 | Jay Satriani PRO This award is truly well-deserved, recognizing the hard work of the entire team, crew, and members of 1x, who consistently deliver extraordinary creations from all corners of the globe. Hopefully, future endeavors will include offline events that foster stronger connections and lead to even greater success. |
| Yvette Depaepe CREW Many thanks, dear Jay! |
 | Anna Cseresnjes PRO great !!!! ... congratulations to you Yvette and your team |
| Yvette Depaepe CREW Many thanks, dear Anna! |
 | Robert Bolton PRO Very well done Yvette. Testament to the hard work that goes into 1x. |
| Yvette Depaepe CREW Many thanks, dear Robert ;-) |
 | Hilda van der Lee PRO Congratulations to the 1x team and dear Yvette, well done and bravo! |
| Yvette Depaepe CREW Thank you, dear Hilda ;-) Up to nr 2 |
 | Elizabeth Allen CREW Huge congratulations to Yvette and the entire editorial team - this recognition is so well deserved for the high quality and content of the articles in the magazine. Thank you for all your efforts, and wishing you every success in the future. |
| Yvette Depaepe CREW Thank you, Elizabeth ... looking forward to the next chapter all together: the 2nd place ;-) |
by Yvette Depaepe
Published the 20st of July 2026
Svetlana Povarova Ree states: 'Contemporary photography is full of beauty, but everything is expected to be perfect. My profession as a journalist has certainly influenced me, and I am aware that the world is not perfect. The most important thing is for photography to evoke thoughts, feelings, and memories. Enjoy this interview with an exceptional photographer and a wonderful woman.

“Yellow lilies”
Dear Svetlana,
Firstly, I would like to thank you for taking the time to answer this questionnaire. Could you please start by introducing yourself briefly, telling us about your hobbies, and describing any other projects you are involved in?
Dear Yvette, I would also like to thank you for inviting me to be interviewed. It’s a great honour and shows that someone is interested in my work. I’m feeling a little nervous as this is the first interview I’ve ever given. Usually, I'm the one asking people for interviews, as I'm a journalist by training.
I was born in the USSR. I studied at Moscow State University named after Lomonosov. After graduating, I worked for various newspapers in Moscow. In 1989, I relocated to Svalbard to pursue a career in journalism. In 1991, I married my Norwegian journalist colleague, Tor Ole Ree. We lived in Svalbard for six years.
I learnt Norwegian so that I could work in my chosen field in Norway. In 1995, we moved to the mainland. Since then, I have had to learn various skills. I have worked as a journalist, photographer, Russian language teacher, translator, and oriental dance teacher.
When you move to a new country, you have to learn lots of new things and often have to start again from scratch.
I love spending time with people and I enjoy photography, reading and dancing. All of these interests proved useful in Norway, and gradually my hobbies became part of my work.
Currently, I work as an interpreter for Ukrainian refugees in Norway. This takes up most of my daytime hours. In 2023, I visited Ukraine. I visited the cities of Lviv, Kyiv and Bucha and wrote a report containing photographs taken there. I worked as a freelancer for our local newspaper for 18 years.
The largest projects I have been involved in were carried out as part of a group that had maintained friendly ties with the Kenyan village of Homa Lime for many years. Our Norwegian group helped the villagers build a community centre complete with a children’s library. I travelled to Homa Lime five times as part of this group.
I have also held four photography exhibitions at the Stiklestad Cultural and National Centre in Verdal.
One of these was called 'Africa is a Woman'. Another featured photographs of Homa Lime taken by my husband and me. The other two featured nature photography and photojournalism.
When and how did you first become interested in photography?
My dad gave me my first camera, a Zenit, when I was 15. He loved photography and passed that love on to me. My husband was a press photographer in his younger days. Tor Ole has helped and supported me a great deal in developing my photography skills. I started working as a journalist for a local newspaper in 1998. As the newspaper had a small staff, I had to take my own photographs for my articles. These were mainly reports and interviews with people. As a journalist, it was photojournalism that interested me the most from the outset.
For many of us, photography is a hobby or a way of life. So, how would you describe your relationship with photography?
Photography started out as a hobby for me, then became a job, and now it’s a way of life. I can't imagine life without it. It's a necessity. I never leave the house without my camera in case I miss a shot or some special light. When I was studying journalism at university, our professor used to say that a journalist’s legs were their bread and butter. That’s why the process of taking photos is so important to me. It’s become a habit.
Which experience has had the greatest influence on your photographic journey so far?
The experience that has influenced me the most is continuous improvement. The more photographs I take, the more skilled I become. I sometimes make mistakes and become discouraged, but I never give up. I keep exploring and striving to improve. Photography is a field in which you can always develop, with new opportunities constantly arising.
Your body of work is very diverse. I see architecture, portraiture and still life photography.
What appeals to you about these different genres?
Yes, I find everything interesting. I think it's important never to stop being amazed by nature. It's a trait that children have, but that adults gradually lose. Photographers, however, seem to retain this ability to see something new in the everyday.
I love taking portraits, but I don't always have access to models. Then there’s street portraiture.
Architecture also comes to life when you find a new angle or some interesting details.
Still life photography is also incredibly fascinating. Sometimes I find myself pondering the composition, and the right solution suddenly comes to me. Light is important in all genres of photography, but particularly in still life. One could say the same about every genre.
I once attended a lecture on still life photography. The photographer talked about his vision of still life. He said, 'When I walk into the kitchen in the morning, I see a kettle and some unwashed crockery. I see a still life.' When I go out onto the street, I see a crumpled ball of paper and a cigarette butt on the tarmac. I see a still life.' That’s how it can be.’ Others think differently. There must be room for all forms of creativity.
Do you value the mood or story behind your images more than technical perfection?
I suppose everything is important: the mood, the story and technical excellence. For me, what matters in photography is that it opens a window on to feelings, thoughts and memories. If photography is an art form, then it should sometimes provoke, in order to stir up certain feelings. When we visit art galleries, we see more than just beauty in the works of the great artists. For example, Edvard Munch’s The Scream, or Francisco Jose de Goya’s paintings, or Hieronymus Bosch paintings. Any feelings other than indifference.
If I’m doing street photography and want to take a photo of a stranger, I smile at them first. It’s rare for anyone not to return a smile, and that’s the start of a connection. But it’s not easy to take photographs in every country. If I’m planning a shoot, I prepare thoroughly. When I was photographing African women who live in our city, I tried to find a new spot every time: in the woods, by a lake, or by a waterfall.
It was a very interesting project, and it was a pity when it came to an end.
Describe your overall photographic vision.
I think I’ve already explained my general approach to photography. Contemporary photography is full of beauty, but everything is expected to be perfect. My profession has certainly influenced me, and I am aware that the world is not perfect. The most important thing is that photography should evoke thoughts, feelings and memories. It should also be a way of painting with light and colours.
Could you tell us more about your creative process, from initial idea to final product?
My creative process always starts with an idea. For instance, I might decide to take a photograph of a new still life. Many factors influence this, such as my mood, the time of year and the objects I want to use to create the composition. I walk around and think about it for a day, two days, or even a week. Then, suddenly, an idea pops into my head. I then start putting the composition together, which can sometimes take a whole day. Yet sometimes, something just doesn’t work out.
Capturing the right light also takes time. Sometimes I work on a still life for several days before finding the right solution.
We currently have two Persian cats at home. Some relatives asked us to look after them. I had the idea of taking photos of the cats by the piano. But the cats weren't having any of it. Every day, I try to take photos of them. Then I sort through them, delete some and take more. I might never manage to get the shot I want. But I’ve tried.
Where do you look for inspiration, and what inspires you the most?
I find inspiration in nature, music and paintings. Even a simple daisy can sometimes inspire me.
Many people believe that the right gear is unimportant if you're passionate about photography. Could you tell us what equipment you use? For example, what camera and lenses do you use, and what lighting and tripod?
I have three cameras (a Leica D-Lux, a Nikon Z 7_2 and a Fujifilm XF) with different lenses, a tripod and a Rotolight. I haven’t found the right camera for me yet. Having three cameras is impractical for holidays or mountain trips. But I’m still looking!
Which is your favourite photo? Please tell us the story behind it.
I don’t think I have a favourite photograph. All of my photos are special to me. That said, you can sometimes fall in love with a particular photo because of the circumstances in which it was taken or the special atmosphere it captures. But that doesn’t mean that other people will like it or that it’s technically perfect. For example, we were in Dharamshala in the mountains in India, where it rains a lot. It was pouring with rain that day.
A shepherd was sitting on a bench in the dreary rain, gazing at the mountains below. Everything around him was grey and shrouded in mist. The shepherd was holding a multicoloured umbrella. I called this photo 'There Are No Grey Days'. The scene was touching and really moved me.
Which photographers or mentors have influenced you the most?
There are many great photographers, each of whom has had an influence. But above all, Robert Capa and Steve McCurry stand out.
As this interview is coming to an end, could you tell us about any photography projects you would like to be involved in?
I don’t have any plans for projects at the moment. Ideally, I’d like to go back to Ukraine and take photographs of the people and everything that’s happening there. But that's not possible while there's a war going on. I’d also like to travel the world and take photos of people, nature, architecture, and animals.
When I interviewed various people, I often asked them: ‘What do you dislike most, and what do you love most?’ I should mention that what I dislike most are wars, dictators and violence. As for what I love most, the answer is simple: peace and love. And photography.
Is there anything else you would like to add? What are your thoughts on using 1X to showcase your work?
I feel lucky to be on the 1x platform. I know I’m not a particularly innovative photographer, but I hope people enjoy some of my work. Either way, I’ll keep working to improve. I am grateful to all the inspiring photographers here. There is a lot to learn from them.

“Old spoon”

“Cloudberries”

“In an orange staircase”

“Quiet look”

“Babushka Natasha”

“Blue spiral”

“A tree and human”

“White star”

“Peach-colored roses”
“Genuine”

“The harvest is harvested”

“Lady and the plant”

“Norvegian style”

“The eye of the stairs”

“Raven and tree”

“Solitude”

“The forest angel”
|
| | Chris Hamilton PRO Congratulations, great images and informative story, nicely done. |
| | Eiji Yamamoto PRO Dear Svetlana, thank you so much for a truly wonderful and inspiring interview! Dear Yvette, thank you so much as always! |
| | ¡Excelente entrevista! He estado siguiendo tu trabajo durante bastante tiempo, y siempre he admirado lo que haces. Felicidades y gracias por compartir tus ideas, fue realmente inspirador. |
 | It’s a wonderful tribute to your photographic work. Congratulations, Svetlana, and thank you, Yvette. |
| | joanaduenas PRO For some years now I've followed Svetlana's excellent work. I consider her a very creative photographer, capable of creating images on diverse subjects with great perfection. Thank you so much for sharing your thoughts, emotions, and reflections in this interview, which, by the way, offers a glimpse into your work and you.
Many thanks to Ivette, my dear friend, for presenting these fascinating interviews. |
| | Rana Jabeen PRO Dear Svetlana, love your work. My best compliments for the feature
Thanks for the interview Yvette |
| | The photographs, the photographer’s sensitivity and the interview are all wonderful. My sincere congratulations, Svetlana and Yvette |
 | MingLun Tsai PRO Dear Svetlana, Congratulations on your outstanding feature! Your diverse and unique work is truly inspiring. Whether it's still life, portraits, or architecture, your artistry always stands out. I'm thrilled to read your stories and see your incredible work recognized on platforms like 1x.com. Looking forward to experiencing more of your creativity! |
 | Gila Koller PRO Dear Svetlana, my best compliments for the interesting and wonderful interview you gave to 1x.com magazine! As someone who follows your work, I really enjoyed reading it and getting to know you better! You are a fantastic photographer, and I truly enjoy seeing your wonderful and diverse photos. Congratulations and best wishes! |
 | UstinaGreen PRO Wonderful galery and selectionh works! Dear Svetlana, congratulations with great interview and many best compliments of works in your showcases! Many thanks dear Yvette, that you make amazing interview of tallented photografer! |
| | Atul Saluja PRO A wonderful article and beautiful series of images. Congratulations and best wishes dear Svetlana. |
| | Robert Bolton PRO Inspiring profile and I love the diversity of images. All have a quiet beauty. |
 | I always enjoy the photographer profiles in the magazine. This article, too, gives me insight into the person behind these beautiful images. The selection of photos is excellent and showcases the creativity and photographic skill you possess, dear Svetlana. Thanks, as always, to Yvette for her work as well. |
 | Great article, and great talented work of Svetlana…congrats |
 | Dear Svetlana, congratulations for this wonderful interview. I enjoyed reading your words and looking at your beautiful images. As you know, I like very much your photography. Congratulations again! |
| | Yvette Depaepe CREW Dear Svetlana, you are such a warm and interesting person. Your first interview is so fine and it is heartwarming to see so much recognition from our community. You're a humble but excellent photographer. Your images all have a big soul, my friend! |
 | Vladimir Funtak PRO “Babushka Natasha” I like best. After reading this interview I will understand your images much better. Congratulations dear Svetlana. |
 | Shenshen Dou PRO Dear Svetlana, I have followed you excellent works for many years, but first time to know you as a such interesting person with exciting life experiences due to your ability to tell stories so well. Thanks you and Yvette make this possible! |
| Yvette Depaepe CREW So glad to hear this shenshen ... This is giving so much satisfaction to ut Svetlana in the spotlight. |
| | Manuel Gayoso PRO Dear Svetlana, congratulations on this interview, it's very nice to know something about the woman behind the objetive, your insights and thoughts on photography. And thank you Yvette as well for this article, |
| Yvette Depaepe CREW Yes, Svetlana is a most interesting person ... it is a pleasure to present her to the readers. |
 | X-FlyingKN PRO Dear Svetlana,
Congratulations on your 1x.com feature! It's wonderful to see your work receiving the recognition it deserves:-) I've always loved your work and look forward to seeing more~
And Thank you Yvette too as always !
|
| Yvette Depaepe CREW Thanks for your appreciation, dear Ken! |
 | congrats Svetlana |
 | Miro Susta CREW Svetlana I love your wonderful photos, superb and most impressive selection in your portfolio, accept please my sincere congratulations, and dear Yvette great thanks for very interesting interview which brought us closer to Svetlana and her lovely photo work. |
| Yvette Depaepe CREW Thank you, Miro! |
| | Great article Svetlana, nice to know more about you and your work. I've been following you and your work since you joined 1X. You are a pleasure to interact with. Warmest regards, Patrick |
 | Streiff Marcel PRO Excellent selection out of your wonderful portfolio Svetlana ! Congratulations ! |
| | Congratulations, love your work. |
 | FranzStaab PRO Kudos and congratulations on this interview. It was interesting for me to know more about you. I always like to be inspired by your work! Keep it up! |
 | Dov Fuchs PRO Congrats, Svetlana! Spectacular images! |
 | Valentina DAmato PRO Big congratulations for this incredible article dear Svetlana!
I really admire your unique and diverse work! |
| | Elizabeth Allen CREW Congratulations on this wonderful feature, dear Svetlana. I am always inspired by your beautiful work, whether still-life compositions, portraits or architecture. I loved reading more about you and seeing so much of your work together here. Thanks as always to Yvette. |
| Yvette Depaepe CREW My pleasure as you know, Elizabeth ;-) |
 | konglingming PRO Congratulations, dear friend. Every one of your works is wonderful |
| | Sokol Priftaj PRO Inspiring article and photos! Thanks so much for sharing. |
by Editor Lourens Durand
Edited and published by Yvette Depaepe, the 17th of July 2026

“Show Time’ by Hasan Baglar
One could argue whether an interest in nature engenders an interest in macro photography, or vice versa.
Either way, it provides a fascinating insight into both.
Macro photography in the insect world requires an understanding of not only the equipment and techniques used, but also of where and when to find your subjects. There are very few lucky shots! Most successful photographs are the result of a careful assessment of camera settings, necessary equipment, lighting setups, and post-processing.
Then there is the question of ethics. Nowadays, it is widely accepted that you should shoot your subject in situ. There is no longer any justification for catching a butterfly and putting it in the refrigerator, rendering it immobile for a few minutes, or freezing it to death. Of course, all insects die a natural death, whether by the hands of a flying assassin or a sniffing one, but the consensus is to let nature take its course. If an insect has died naturally, it is OK to use it as a macro subject!
Nevertheless, the live opportunities are manifold and better in the cooler mornings and evenings when insects are more sluggish.
The quality of the equipment is crucial. It can make or break a great photo. This applies to photos of nature subjects. It also applies to photos of other small things taken in a studio.
Although mobile phone technology has advanced to the point where it can successfully perform macro photography, it is clear that conventional cameras with their larger sensors and plethora of settings, together with macro lenses and their advanced optical properties, are superior.
The settings required for excellent macro photography would fall within the following ranges:
o Iso: as low as possible without generating excessive noise – max 1600 in handheld situations, but 120 would be OK with a tripod
o Shutter speed needs to be at 1/120 second if handheld. With a tripod, a slower shutter speed is possible provided the subject is static
o F-stop of 1/11 or 1/16 is generally used.
o Ideally, the subject should be sharply in focus, with the background blurred.
To achieve front-to-back sharpness in larger specimens, photo stacking is used – a process involving taking a number of shots focused at different distances from the camera, from closest to farthest, typically at an f-stop of around 1/5.6. This can be achieved by using a set of movable bellows between the camera and lens, or by using a focusing rail, and then blending the photos using software such as Zerene Stacker or Helicon Focus.
Although many newer cameras have built-in focus stacking capabilities, you will still need stacker software.
As is often the case in photography, lighting is of prime importance. This applies to both quantity and quality. Natural light is ideal, but it often creates shadows in the wrong places. This can be overcome by using an on-camera flash, but this can cause glare and uneven lighting. This can easily be overcome by adding a diffuser to the flash unit. The one I use is a mini 16 x 16 cm soft box that is fixed to the flash unit with elastics.
In conclusion, as with any other photographic endeavour, mistakes will be made and lessons will be learned along the way. The four key things to remember on your journey are Patience, Persistence, Precision and Preparation.
Here are some stunning macro photographs from the 1x archives.
Happy shooting!

"The smell of you" by Atul Saluja

“The Duel on the Vine’ by Atul Saluja

‘Dry leaf and Bubbles’ by Lydia Jacobs

“Robber Fly” by Miron Karlinsky

“Euchloe belemia” by Miron Karlinsky

“Starless” by El Filósofo

“The winner of the summit…” by Thierry Dufour

“Relax break” by Thierry Dufour

“Autumn rain” by Thierry Dufour

“Green Veined White” by Peter Davidson

“Threat display” by Jimmy Hoffman

“Robber Fly” by Lourens Durand

“Curious Yellow Car” by Alexander Zubrickij

“Mantis” by Lourens Durand

“Bee on Aloe HR” by Lourens Durand

“…..Element on sewing machine…..” by Johanes Januar

"ABw048” by Johanes Januar

“Dew Bells” by Jacky Parker

“Delicate Insect Balance” by Thierry Dufour

“Swallowtail” by Jimmy Hoffman

“Ration” by Andyan Lutfi

“chili cilider team” by Yahia Taufikurrahman

“Lost” by Jimmy Hoffman

“Dewdrops are the GEMS of morning” by Yvette Depaepe

"Heart of a Rose" by Peter Davidson

“Stinkbug HR” by Lourens Durand

“Rain” by Mustafa öztürk

“Little Secret” by Wil Mijer
|
 | Dazhi Cen PRO A detail exploration and demonstration of the insect world! |
 | DonnaHom APA PRO I fully enjoy every image exhibited here. Thank you for putting the macro edition together. |
| | Jay Satriani PRO Everything looks absolutely stunning; I am so grateful to witness the lives of these tiny, beautiful creatures—works of art in themselves. Thank you, God, and thank you, Laurens—you are amazing. |
 | Greetje van Son PRO I viewed these magnificent images with great pleasure and awe. My compliments to every photographer in this splendid series. Thanks to Laurens for this beautiful collection and to Yvette for publishing. |
 | Benny Pettersson PRO Thank you for a great article that provides inspiration. |
| | Great article |
| | Miro Susta CREW wonderful collection of beautiful macro pictures, thank you Laurens and Yvette for creating, editing and publishing it. |
| Yvette Depaepe CREW Thanks a lot, Miro !!! |
 | Emel Sefer PRO Congratulations |
 | Wonderful article, full of impressive and inspiring macro images... A real feast to the eyes. Congratulations to the featured photographers, and to Lourens and Yvette for creating this insightful magazine article. 👏👏 |
| Yvette Depaepe CREW Thanks for your appreciation, dear Carolina !!! |
 | Jimmy Hoffman PRO Very nice article. Thanks for choosing a couple of my shots!
have a great weekend. |
| Yvette Depaepe CREW Your work couldn't be missed here, Jimmy ;-) |
| | Sokol Priftaj PRO Really enjoyed reading this article. Thanks for sharing |
| | Sokol Priftaj PRO Really anjoyed reading this article. Thanks for sharing |
| | Peter Davidson CREW Excellent piece and thank you for choosing a couple of my shots! |
| Yvette Depaepe CREW Our pleasure, Peter! |
 | many thanks to editors, great collection !!! |
 | Thierry Dufour PRO Thank very much dear Yvette and Lourens for selecting my images. A magnificent series of macro shots. |
| Yvette Depaepe CREW Thanks for your appreciation, Thierry ... well deserved selection! |
 | Hai Lin 雪原 PRO Great collection of macro works, thanks very much to editors!! |
| | Robert Žumer PRO Excellent article. |
| | Great article, thanks for the info and wonderful images! |
| Yvette Depaepe CREW Thanks for your appreciation, Patrick ... |
| | Atul Saluja PRO Wonderful article and very well summarized dear Lourens. An excellent series of images shared from 1X. Thank you for highlighting a couple of my images. Many thanks to Yvette as well for facilitating. |
| Yvette Depaepe CREW Thank you dear Atul ;-) |
by Yvette Depaepe
Published the 15th of July 2026
'Eccentric Photography'
For photographers a free spirited pursuit can lead to the most original and memorable photographs. Leaving the comfort of familiar subjects is a challenge, yet an exciting way to grow as an artist.
Stunning and original images were submitted.
The winners with the most votes are:
1st place : Udrea Dan
2nd place: Adolfo Urrutia
3rd place : Hadi Malijani (Malenjani)
Congratulations to the winners and honourable mentions.
Thanks to all the participants in the contest 'Eccentric Photography'
Next theme will exceptionnally start on Monday the 20st of July.
You have a few days extra to think about the new challenge : 'Full Frame Photography'.
In photographic composition, the 'frame' refers to the rectangular view you see through your camera. When using this technique, you simply fill the frame with more of your subject, thereby reducing the amount of background or negative space shown.
This contest will end on Sunday the 2nd of August at Midnight, like it used to be in the past.
The sooner you upload your submission the more chance you have to gather the most votes.
From Monday morning on you will be able to uploaded your photo here.

 2nd place : by Adolfo Urrutia
2nd place : by Adolfo Urrutia 3rd place : by Hadi Malijani (Malenjani)
3rd place : by Hadi Malijani (Malenjani)

 Martin Kucera EFIAP AZSF
Martin Kucera EFIAP AZSF by Olexandr Shpyek
by Olexandr Shpyek


|
 | Yanny Liu PRO Such collection of Creative pictures. Congrations to all the winners! |
| | Creativity at its finest! My sincere congratulations to the winners and honorable mentions. And kudos to Yvette and the 1x management team for running these photo contests. 👏 👏 |
 | Congratulations to all the winners and honorable mentions! Thank you, dear Yvette and the entire 1x team, for your dedication and for making these inspiring contests possible |
| Yvette Depaepe CREW thank you so much for your appreciation, Hadi! |
 | Fiorenzo Carozzi PRO Astonishing images. Congratulations to the authors |
 | Ótima diversão na composição das imagens. Talento quanto baste. |
 | Michel Romaggi CREW Excellent selection! So much creativity and humor. Congratulations to all the participants |
 | Jane Lyons CREW There is so much fabulous humor and creativity here. Congratulations to everyone who entered. |
by Yvette Depaepe
Published the 12th of July 2026
James Cai's portfolio is intentionally diverse. Rather than being defined by a single genre, it reflects the people, places, wildlife, architecture, landscapes and moments that have inspired him during his travels. Each image is a photograph that represents an experience and a story from somewhere in the world. Join me on a visual journey through James's amazing body of work.

‘Antarctic Fire Gate’
Dear James, firstly, I would like to thank you for taking the time to answer this questionnaire. Could you please start by introducing yourself briefly and telling us about your hobbies and any other projects you are involved in?
Thank you for the invitation, Yvette. It is a great honour to be interviewed by such a renowned art platform as 1x.com. Over the years, I have found endless inspiration and encouragement within the 1X community and learnt a great deal from its diverse and talented pool of photographers.
I have lived and worked in the greater Chicago area for many years. While my professional career is outside the art world, I have been a lifelong admirer of the visual and performing arts. Photography has become a vital extension of this passion, offering me a way to engage with the world more deeply.
To me, light feels like a guiding destiny, and photography is its visual poetry, transforming fleeting moments into lasting expressions of emotion and meaning.
How and when did you start your journey in photography?
My journey in photography began over thirty years ago with a simple point-and-shoot camera. I used it to capture fragments of family life: travel days, children’s laughter and those ordinary moments that fly by. Initially, photography was never about art, only about preserving memory. Yet beneath that simple joy, a creative question slowly emerged: why did these images so often fail to capture the life and emotion I had experienced in those moments?

‘A Lightning on the Butte’
In 2016, I attended a photography forum hosted by an international group of celebrated artists. It was there that I stepped into a wider world of vision and intention. It was an awakening. I was introduced to the language of composition, the poetry of light, the rhythm of framing and the subtle craft of pre-visualisation and post-processing. I began to follow the light more deliberately, waiting for the right moment rather than chasing it, and listening to the quiet dialogue between the subject and its shadow. Post-processing became a form of interpretation and expression. Photography became less of a hobby and more of an integral part of my being — a continuous unfolding of attention and emotion.

‘Veil of the Waterfall’
Today, I see myself as a humble chaser of light. I am still learning and searching, and I am still moved by the silent poetry hidden in everyday life.
For many of us, photography is a hobby or a way of life. So, how would you describe your relationship with photography?
By immersing myself in the world of photography, I gradually developed a heightened sensitivity to light, shadow, shape and form, almost like a sixth sense. Over time, I began to see the world through the lens of photography, using it to observe living beings and the environment around me.

‘A Tree’
This shift brought with it an extraordinary ability: the capacity to sense a place's subtle vibrations and feel a moment's atmosphere before it fully unfolds. Photography became a means of capturing fleeting moments, transforming ordinary, passing instants into concentrated emotional expressions.

‘Splash of a Lightning’
On this journey, light feels like a guiding destiny: ever-shifting yet always leading the eye and spirit forward. In turn, the camera becomes my pen, a tool that can express what words often cannot and give shape to the silent conversations between perception and feeling.

‘A Sunset Rhapsody’

‘Roots of the Earth’
Which experience has had the greatest influence on your photographic journey so far?
In 2017, I went on my first photography tour, led by Jeffrey Wu. We spent two weeks in Kenya, particularly in the Maasai Mara Conservation Area. This was my first time encountering wild animals in their natural habitat, and it was a truly eye-opening experience. Unlike my previous travels, which had taken me to many parts of the world, this journey was deeply rooted in untamed nature, offering a raw, unfiltered connection with life in the wild.
I took countless photos during the trip, but more importantly, it changed the way I saw and approached photography. One of those photographs was the first image I had featured on 1x.com, and it became the most liked photo in my portfolio.

‘Breakthrough’
That experience was a turning point for me. It strengthened my technical skills, deepened my emotional connection to photography, and confirmed my passion for telling stories through the natural world.

‘Mom and Cubs’
You have a diverse body of work. I see wonderful landscapes, stunning aerial shots, and beautiful wildlife photography. What draws you to these different genres?
Travel is a big part of who I am. I prefer to explore the world and experience different cultures, landscapes and ways of life rather than travelling with a specific photographic subject in mind. Although photography often accompanies our travels, it is not always the main reason for going somewhere.
This approach naturally leads to opportunities to photograph a wide variety of subjects, both within and beyond our comfort zones. Consequently, my portfolio is intentionally diverse. Rather than being defined by a single genre, it reflects the people, places, wildlife, architecture, landscapes and moments that have inspired me on my travels. Each image represents an experience and a story from somewhere in the world, as well as being a photograph.

‘A Playing Scene’
Which is more important to you: the mood or story behind your images, or technical perfection?
Although both are important in the creative process, I would prioritise story or mood over technical perfection. To me, photography is primarily about conveying emotion and/or meaning rather than achieving flawless technical execution.

‘My meal too!’
I often think of it in terms of music. The composer writes the musical score, which sets out the structure, story and emotional foundation of the piece. However, it is the conductor and musicians who breathe life into it, interpreting it with technical skill and personal expression.
Similarly, an image may rely on technique, but it is the underlying story that gives it soul. The story forms the invisible foundation that carries emotion and energy, while technical elements simply serve to support and express it. Without an emotional core, even the most technically perfect image can feel empty.
Do you carefully select the locations at which you intend to take photographs?
I value spontaneity and action when it comes to capturing the moment as it unfolds. Before a project, I usually scout the landscape using Google Maps, or research potential subjects online. This preparation helps me to understand the environment better while still allowing room for intuition and the unexpected in the field.

‘Chicago Shoreline and Frozen Lake’

‘Frozen Lake Michigan’
What is your relationship with your subject matter, aside from being an observer?
Photography is not just about observing the subject; it's also about sensing the relationship between the subject, its surroundings, and the frame. The photographer brings these elements together to express his personal view of the scene.
In photography, therefore, I see myself not only as an observer, but also as an emotional interpreter — someone who feels as well as sees, and who translates those feelings into a visual form.

'Night Owl Monkeys’

‘Curiosity’
Describe your vision for your photography.
A good photograph can capture the viewer’s attention, evoke a tangible emotion and convey a touching narrative. A meaningful image can also encourage people to think, imagine and reinterpret what they see. As an observer, I have come to see photography as a constantly evolving art form that is no longer limited to the faithful recording of reality, but is opening itself up to more experimental and expressive possibilities. Through mixed media and other as yet undefined possibilities, photography continues to expand the language of visual storytelling.

‘Flying Rose’
Where do you find inspiration, and what inspires you most?
I do not see art as an isolated form. Instead, I believe that different art forms are closely connected and can influence one another. As well as photography, I have joined a community choir and played musical instruments, which has helped me to develop a better understanding of rhythm, emotion and expression.
I have also helped to set up a small theatre for a drama group and often attended theatre performances, which provided valuable experience in stage lighting, storytelling and performance space. I also often visit classical and contemporary museums to find inspiration and observe different forms of artistic expression.

‘The Dance’
Through these experiences, I have come to see art as a shared language. Music, performance and visual art all express human emotion differently and continually enrich each other.
Many people believe that the right gear is unimportant if you're passionate about photography. Could you tell us what equipment you use? For example, what camera and lenses do you use, and what lighting and tripod?
I use the Sony A1 and Sony A7R IV for wildlife and landscape photography. For video projects, I work with the Sony A7SIII series. In addition, I have built a range of Sony lenses that support different creative needs, from wide-angle landscapes to telephoto wildlife work. For aerial perspectives, I use the DJI Mavic 4 Pro, which adds another dimension to my visual storytelling and allows me to explore scenes from a unique and elevated viewpoint. I have a full studio setup with an array of photo lighting equipment.

‘Sunshine glazed Cerro Torre’
Which is your favourite photo, and what is the story behind it?
My wife and I recently travelled to Australia and New Zealand, visiting many locations that are well known in the world of photography. Because of this, I did not expect to take any truly exceptional photos.
One evening, however, I found myself at the Church of the Good Shepherd, photographing a night scene. This place has been photographed countless times and widely shared across the internet. It had rained all day, and by sunset the sky was still covered in clouds and there was a strong wind, so conditions were far from ideal. However, at around 7.30pm, the wind began to clear the clouds, revealing a vast, open sky above us. The Milky Way emerged in all its glory. There was also unusually strong geomagnetic activity at that time, and aurora lights began to appear. Amazingly, the Milky Way and the aurora were visible in the same shot, arcing above the quiet silhouette of the old church.

‘Southern Rhapsody’
The rare convergence of two natural elements transformed a familiar scene into something extraordinary and deeply personal. It reminded me that, as in travel, the most memorable moments in photography often arrive unexpectedly, as if nature itself were offering a brief, generous reward for patience and presence.
Which photographers or mentors have influenced you the most?
I was fortunate to meet my mentor, John Fan, who has lived close to me for the past decade. He has had a deep influence on me in all aspects of photography, from observing a scene to understanding the essence of a good image.
I also participated in several photography tours with Yiming Hu and Marc Adamus, which provided me with valuable insights into landscape photography and helped me to further refine my technical and creative approach.
On a personal level, I greatly admire Sebastião Salgado and his work.

‘Morning in Torres del Paine’
|
| | Jay Satriani PRO It is truly amazing; everything looks incredibly beautiful and breathtaking. Five minutes per image isn't enough time for me to fully capture and store it all in my memory. thank you dear friend James cai |
 | Vasil Nanev PRO Fantastic work, thank you ! |
 | Kathryn King PRO Truly amazing work. I love the tidal tree and all the images, just wonderful. |
 | James Zhen Yu PRO 恭喜 恭喜 |
 | Lucie Gagnon CREW Wow! Such an impressive and diverse body of work! Magnificent images! Congratulations! 👏👏👏 |
 | Jun Zuo PRO Congratulations, my friend! Great works! |
| | UstinaGreen PRO Super artistic works! The diversity of m and the power of nature in the best execution! Many best compliments and congrats! |
 | Adrian Donoghue PRO great work! |
 | Louise Xie PRO Congratulations brother 🎉 You really deserved👍 |
 | Zhang Dong PRO Congratulations! Amazing artwork! |
 | Best of the best - An exhibition representing the top of 1X 👍 |
 | Leah Xu PRO A truly gifted photographer with an exceptional artistic eye. Congratulations! |
 | Chao Feng 天馬 PRO Impressive body of work. Well deserved, congratulations 🎉 |
| | Yanny Liu PRO Love your pictures. Such grand, majestic feel while beautifully capturing of the landscapes. And spirit and vitality of the animals. Congratulations on your wonderful work! |
| | Yanny Liu PRO Love your pictures. Such grand, majestic feel while beautifully capturing of the landscapes. And spirit and vitality of the animals. Congratulations on your wonderful work! |
 | Hanping Xiao PRO Congratulations my friend. you are well deserved! |
 | Ruiqing P. PRO Congratulations, my friend! This recognition is truly well deserved. Your outstanding landscapes and wildlife images speak for themselves, reflecting years of dedication, patience, and artistic vision. Wishing you many more unforgettable moments behind the camera! |
| | Sublimes photos, congrats |